Abstract
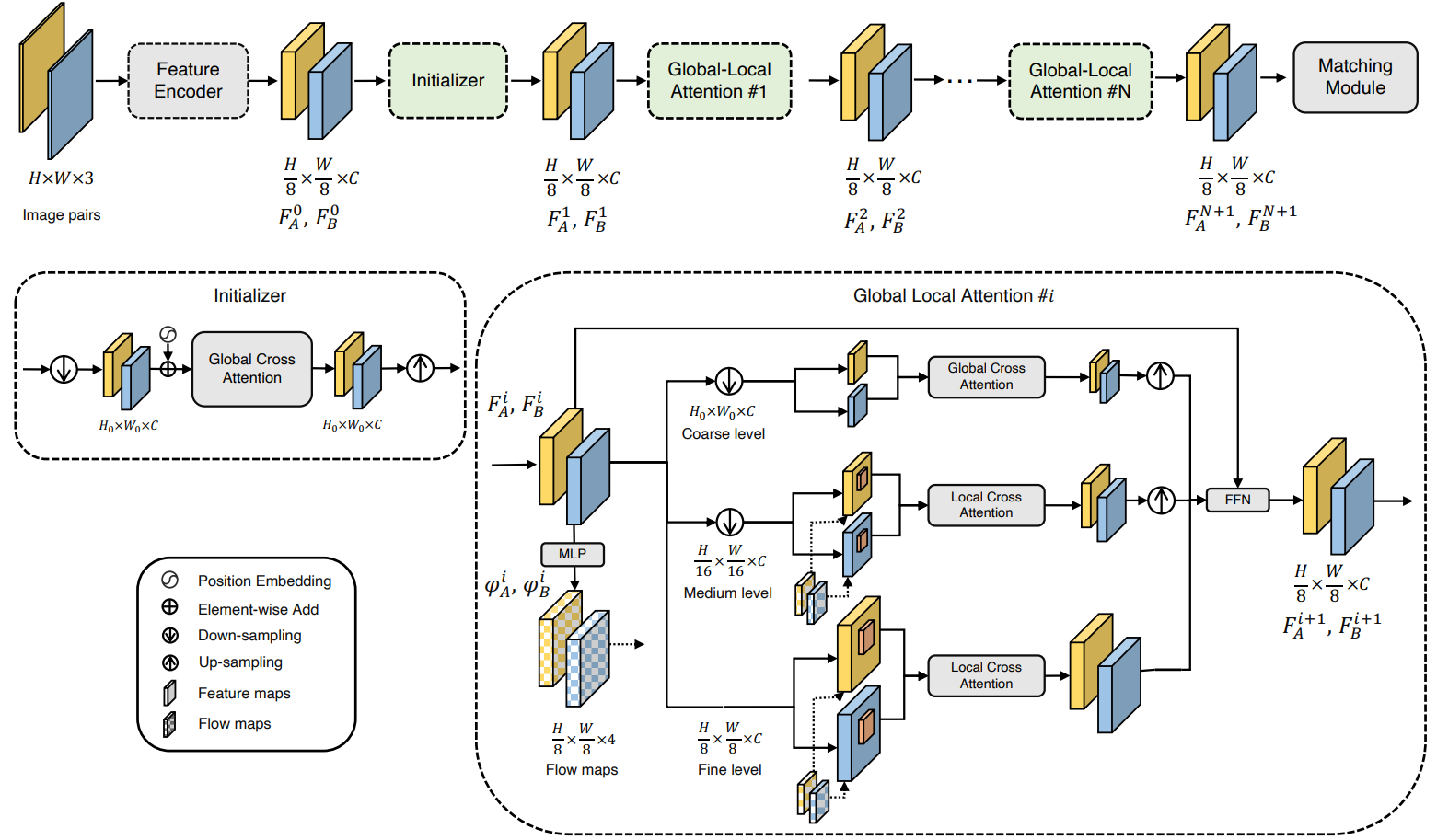
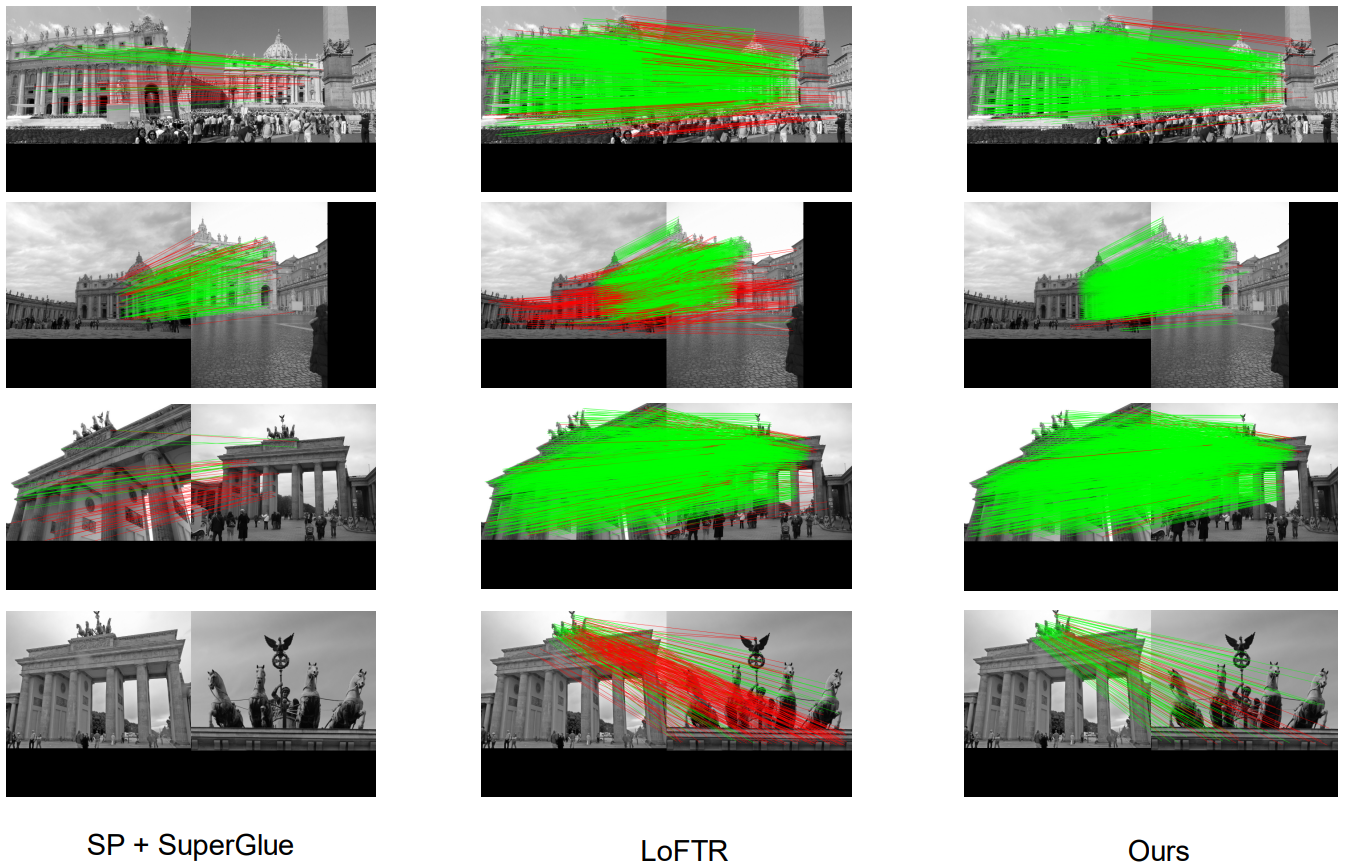
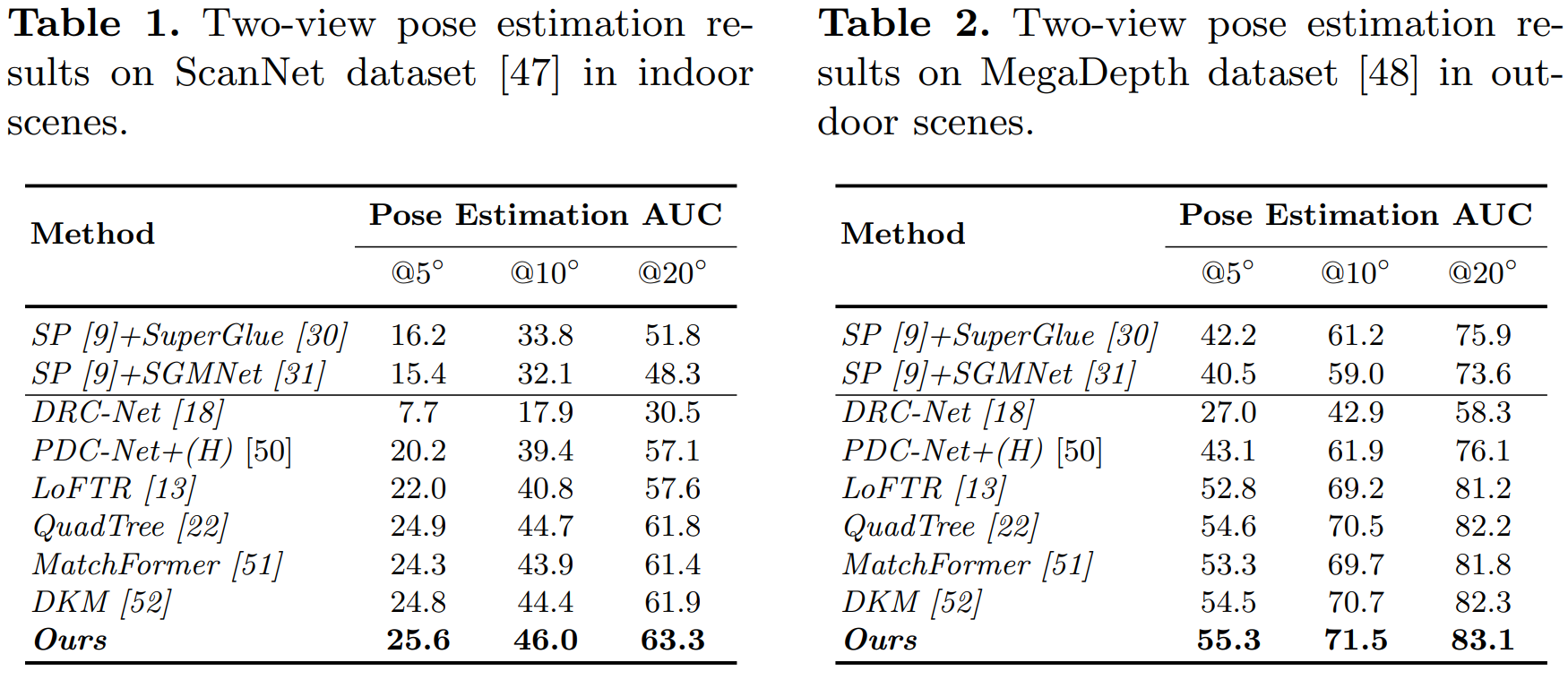
Generating robust and reliable correspondences across images is a fundamental task for a diversity of applications. To capture context at both global and local granularity, we propose ASpanFormer, a Transformer-based detector-free matcher that is built on hierarchical attention structure, adopting a novel attention operation which is capable of adjusting attention span in a self-adaptive manner. To achieve this goal, first, flow maps are regressed in each cross attention phase to locate the center of search region. Next, a sampling grid is generated around the center, whose size, instead of being empirically configured as fixed, is adaptively computed from a pixel uncertainty estimated along with the flow map. Finally, attention is computed across two images within derived regions, referred to as attention span. By these means, we are able to not only maintain long-range dependencies, but also enable fine-grained attention among pixels of high relevance that compensates essential locality and piece-wise smoothness in matching tasks. State-of-the-art accuracy on a wide range of evaluation benchmarks validates the strong matching capability of our method.